La arquitectura de microservicios, o microservicios sin más, es un estilo de arquitectura que está compuesta de una serie de servicios de pequeño tamaño cuya funcionalidad específica está bien definida, débilmente acoplados entre ellos, se comunican mediante protocolos ligeros y se desarrollan, despliegan y mantienen independientemente por equipos pequeños.
Se podrían considerar un sistema distribuido con todas las ventajas e inconvenientes que conlleva. Se comunican entre ellos mediante REST de forma síncrona o mediante un servicio de mensajería como Kafka de forma asíncrona. Los mensajes intercambiados podrían ser en diferentes formatos como JSON, AVRO, Protobuf, etc.
1. Características de la arquitectura de microservicios
A continuación mostramos las características que definen a una arquitectura de microservicios.
Independientes
Son independientes entre sí, manejando su propio dominio específico, con un nivel bajo de acoplamiento y una alta cohesión. Un equipo pequeño puede hacerse cargo de uno o varios microservicios. De esta forma también podemos analizarlos, desarrollarlos, probarlos y desplegarlos de manera individual.
Al ser componentes individuales pueden ser intercambiados de manera independiente, sin que el resto del sistema se resienta. También se pueden hacer tests individuales, pudiendo detectar cuellos de botella o problemas de rendimiento a nivel de microservicio.
Uso de diferentes tecnologías
Pueden ser desarrollado con lenguajes de programación diferentes. Las bases de datos usadas por cada microservicio también pueden ser diferentes. Los datos manejados por cada microservicio puede ser expuesta mediante un API REST para ser accesible por los demás microservicios.
Por ejemplo, un microservicio puede estar implementado en Java y usar una base de datos Oracle, mientras que otro puede estar implementado en Python con un patrón CQRS con MongoDB para las querys y PostgreSQL para los commands.
Identificación única y descubrimiento
Deben tener una identificación, como un nombre, para poder registrarse en el ecosistema y ser descubiertos por los demás microservicios. Así nos abstraemos de dominios, IPs y puertos específicos de cada microservicio. Los roles que pueden tener los microservicios al respecto son registro, proveedor o consumidor del servicio.
El descubrimiento puede realizars de dos formas diferentes: del lado del cliente, el propio cliente tiene que registrarse e indicar que está operativo cada cierto tiempo, o del lado del servidor, en el que el propio servidor descubre y registra los cliente.
Alta disponibilidad y autoescalados
Mediante la alta disponibilidad creamos microservicios resilientes, es decir, se pueden levantar varias instancias. Si una de ellas se rompe, tenemos la posibilidad de usar las restantes instancias levantadas.
Al ser autoescalados, dependiendo de la carga de trabajo, las instancias automáticamente se incrementarán o se reduciran.
Transacciones distribuidas
Las transacciones que involucran a varios microservicios se consideran distribuidas. Es necesario una gestión apropiada de estas transacciones distribuidas. Puede involucrar varios tipos de operaciones, como operaciones en base de datos o envío de un mensaje a un servicio de mensajería.
Para solucionarlo se utiliza el patrón saga que permite hacer un seguimiento de la transacción mediante orquestación o coreografía. En caso de fallar una de las operaciones se deben compensar las operaciones previas ejecutadas (similar a un rollback en base de datos) para llegar al estado consistente anterior.
Un problema sería la consistencia eventual del sistema. Puede que se hayan completado las primeras operaciones del sistema, pero aún queda alguna pendiente. Esto hace que al visualizar los datos sean inconsistentes en un intervalo de tiempo determinado.
Con estado o sin estado (stateful o stateless)
Un microservicio con estado mantendrá almacenado, bien en memoria, base de datos u otro, los procesamientos realizados anteriormente, siendo accesible y expuesto a los demás microservicios. Así podemos conocer el estado actual del sistema, incluso estados anteriores si se usa el patrón Event Sourcing.
Un microservicio sin estado no almacena nada sobre los procesamientos realizados. Cada operación se realiza de manera independiente de las otras. No conocemos el estado actual ni pasado del sistema, pero a cambio el procesamiento suele ser más sencillo y rápido al no tener que persisitr los datos, y la escalabilidad es mucho mayor.
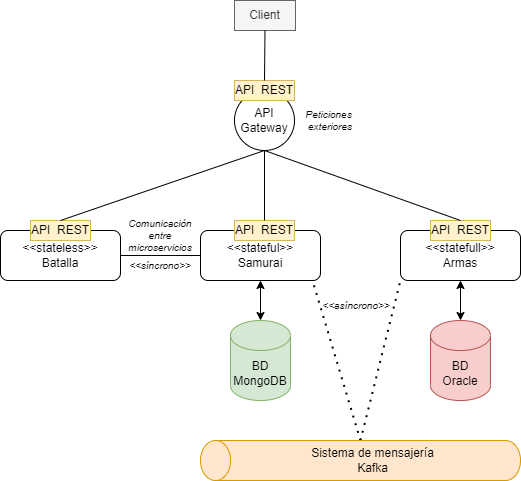
En el siguiente esquema de ejemplo (con Samurais, como no) se puede ver cómo quedaría una arquitectura de microservicios:
2. Tecnologías usadas en los microservicios
En cuanto a tecnologías usadas para implementar microservicios, desde el punto de vista de Java, nos centraremos en Spring, ya que es el framework más ampliamente utilizado.
Spring framework
El objetivo principal de Spring framework es simplificar la creación de proyectos Java (incluídos otros lenguajes basados en la JVM, como Groovy y Kotlin). Es open source. Soporta un amplio rango de aplicaciones, como aplicaciones de empresa, microservicios que se ejecutan en la nube o aplicaciones standalone que nonecesitan servidor.
Sus módulos más importantes son:
- Spring Core: es la pieza central de Spring. Se encarga tareas como gestionar el contenedor de inyección de dependencias, manejar los recursos, validaciones y logging, entre otras funciones.
- Spring Web MVC: se encarga de implementar el patrón MVC (Modelo-Vista-Controlador)
- Spring Data: integración de bases de datos, tanto SQL como NoSQL, creando implementaciones Repository directamente desde interface, usando convenciones para generar querys directamente del nombre de los métodos.
- Spring Security: provee autenticación, autorización y protección contra ataques comunes (por ej. CSRF). Ofrece integración con otras librerías para simplificar su uso, como Spring MVC.
Spring boot
Spring boot es un framework para crear aplicaciones creadas en Java orientadas a microservicios. Su objetivo es reducir la longitud del código y simplificar el desarrollo con respecto a Spring proporcionando una configuración automática. Sus módulos más importantes, llamados starters que se encargan de gestionar las dependencias concretas, son:
- Web: usado para el desarrollo de aplicaciones web. Permite crear aplicaciones HTTP autocontenidas con un servidor embebido como Tomcat. Para ello usaremos el starter spring-boot-starter-web. Si queremos crear una aplicación web reactiva usaremos spring-boot-starter-webflux.
- Data: usado para integrar bases de datos, tanto SQL y NoSQL. Existen dos formas de acceder a los datos, mediante JDBC (haciendo uso de JdbcTemplate) y mediante JPA (haciendo uso de los Repositories). Para el primero se usa el starter spring-boot-starter-jdbc y para el segundo el spring-boot-starter-data-jpa.
- Messaging: usado para integrar sistemas de mensajería. Tenemos los siguientes starters principales:
- spring-boot-starter-artemis: integra el sistema de colas JMS de Java mediante JMSTemplate.
- spring-boot-starter-amqp: integra el sistema de mensajeria RabbitMQ mediante RabbitTemplate.
- spring-kafka: integra la plataforma de streaming de eventos distribuídos. No hay starter, simplemente añadir la dependencia de kafka. Se usa mediante KafkaTemplate.
Spring cloud
Spring cloud proporciona herramientas para construir rápidamente algunos de los patrones comunes usados en un sistema distribuido. Mediante esta tecnología podemos abordar la mayoría de las características explicadas anteriormente como configuración distribuida, servicio de registro y descubrimiento, enrutamiento, comunicación entre microservicios, balanceo de carga, patrón circuit breakers, mensajería distribuida entre otros. Para implementarlo usaremos:
- Spring cloud config: nos permite externalizar la configuración de un sistema distribuido, por ejemplo en un repositorio compartido GIT. Se usa incluyendo la anotación @EnableConfigServer.
- Spring cloud netflix: anteriormente llamado Eureka. Nos permite registrar y descubrir microservicios. Se usan dos anotaciones para implementarlo: @EnableEurekaClient y @EnableEurekaServer, el primero para configurar el cliente y el segundo el servidor.
- Spring cloud circuit breaker: provee una abstracción del patrón circuit breaker, gestionando los reintentos de peticiones entre microservicios. Puede implementar Resilience4J. Para configurarlo se necesita incluir el starter spring-cloud-starter-circuitbreaker-resilience4j.
- Spring cloud gateway: permite enrutar a las diferentes APIs de los microservicios además de funcionalidades cross, como seguridad, monitorización, resiliencia y balancear la carga. Para configurarlo se necesita incluir el starter spring-cloud-starter-gateway.
- Spring cloud openfeing: permite crear un cliente REST de forma declarativa. A partir de una interface se crea la implementación dinámicamente. Se usa incluyendo la anotación @EnableFeignClients.
3. Ventajas e inconvenientes de la arquitectura de microservicios
Ventajas
Entre las ventajas de usar una arquitectura de microservicios tenemos:
| Mantenimiento y testabilidad | Cuando tenemos que realizar un cambio simplemente tendremos que modificar y desplegar el microservicio afectado, y no todo el servicio con su redespliegue más grande y pesado. Las pruebas están muy delimitadas a la función del microservicio. |
| Funcionalidad delimitada | Un nuevo desarrollador al ocuparse de uno o pocos microservicios podrá entender más fácilmente lo que hace cada uno de ellos funcionalmente, al tener cada uno unos límites funcionales bien marcados. |
| Escalabilidad | Como el sistema está compuesto de varias pequeñas piezas, podemos monitorizarlas de manera independiente. Esto nos permite detectar cuellos de botella o microservicios con una alta carga que podemos escalar, incluso de forma dinámica, para que el rendimiento no se vea afectado. |
| Versatilidad | Permite el uso de diferentes lenguajes de programación, así como tecnologías de bases de datos o de mensajería. Permite tener piezas desacopladas mediante la comunicación asíncrona (EDA, Events Driven Architecture), así como la comunicación asíncrona mediante API REST. |
| Reusabilidad | Las piezas creadas, tanto propias como de terceros, son más fácilmente reutilizables. Existen servicios como el API Gateway, de monitorización, autenticación y trazabilidad de terceros listos para ser usados en nuestro sistema. |
| Ágil | Debido a la naturaleza de separar la funcionalidad y crear piezas más pequeñas se adapta muy bien a la metodología ágil. También fomenta el uso del ciclo de DevOps. |
Inconvenientes
Entre los inconvenientes de usar una arquitectura de microservicios tenemos:
| Complejidad | Al ser un sistema distribuido hereda su complejidad, teniendo que manejar las dependencias entre microservicios, comunicación entre ellos, transacciones distribuidas, coordinación en el despliegue, entre otras. |
| Desarrollo y pruebas | El desarrollo es más complicado ya que los desarrolladores deben desarrollan un conjunto de habilidades no triviales. Las pruebas, en particular las de integración, al poder ser transversales a varios microservicios son más complejas. |
| Congestión y latencia de red | Aún estando en el mismo servidor, se requiere realizar esa comunicación entre microservicios, aumentando el tiempo de comunicación. Si el servidor está distribuido geográficamente la comunicación podrá resentirse incluso más. |
| Consumo de recursos | Al disponer de muchos y pequeños microservicios, cada uno de ellos consumen su propia CPU y memoria, lo que implica un gasto de recursos adicional. |
| Integridad de datos | Al hacer uso de transacciones distribuidas puede que los datos de un microservicio aún no lo contemple, mientras que otros sí. Es muy importante conocer cuando ha fallado una transacción distribuida para poder compensar las operaciones ya realizadas y volver al estado previo consistente del sistema. |
Conclusión
Hemos visto qué es una arquitectura basada en microservicios, pudiéndose considerar un sistema distribuido. Entre sus características principales se encuentran que son independientes, se pueden utilizar diferentes tecnologías, se identifican únicamente y se descubren entre ellos, tienen una alta disponibilidad y se autoescalan cuando lo necesitan, manejan transacciones distribuidas y por último pueden ser con o sin estado.
Em cuanto a las tecnologías utilizadas en el ecosistema Java nos hemos centrado en Spring, junto con Spring boot y Spring cloud. Por último hemos hablado de las ventajas e inconvenientes que presenta esta arquitectura.